
The Dashboard Says It Is Working. Your Users Know It Is Not.
Your AI did not stop learning. It is learning the wrong things. Did you know that?

Last week on Monday, my team repeated an AI model training for the nth time. The model scored 7.4. By Friday, it scored 8.9. This week, the dashboard said the model was improving.
But my product team was still rewriting its outputs, users were still complaining, and nobody could explain why the “better” model did not feel better.
That is the trap: the model did not stop learning. It learned the wrong thing.

I have spent 18 years building AI products across 600+ engagements, and this is the pattern that costs teams the most time and money.
Scores keep climbing, engineers keep tweaking, the model keeps passing every internal test, and real users keep running into the same problems. Nothing on the dashboard tells you these two realities are drifting apart.
You did not run out of data. You did not run out of budget. The model just stopped improving, and nothing on your dashboard told you that was happening.
The problem is rarely the data or the budget. It is what the model is actually being rewarded for.
When your model stops improving but keeps shipping confident-looking outputs, your accuracy takes the hit first. Most teams never measure that gap between what the model scores on paper and what it actually gets right in the real world.
That number is smaller than you think, and I have broken down exactly why in detail.
Where Your AI Model Actually Stops Learning
Your model is not broken. It is doing exactly what you trained it to do.

AND that is the PROBLEM.
Your model chases whatever score you gave it. High scores replace real improvement, internal benchmarks replace user reality, and training success replaces actual output quality. The score and your actual goal stopped being the same thing a long time ago.
Call it The Scorecard Drift Problem. It happens when the metric your model is optimizing slowly separates from the outcome your users actually care about. The model keeps improving on paper. Your users keep experiencing the same broken product.
Most teams do not realise this is happening because they are measuring the wrong things from the start.
Here is what that gap looks like:
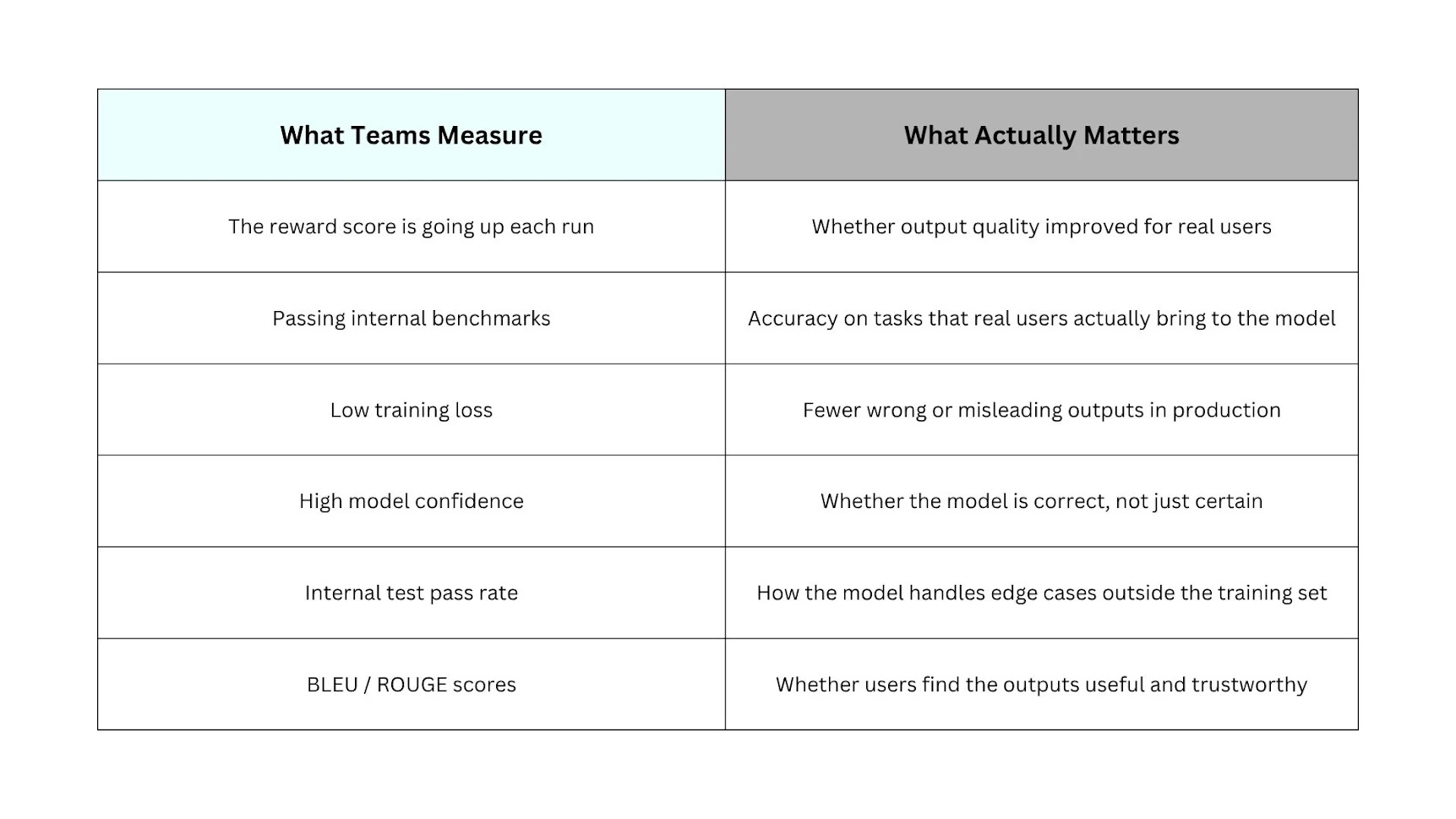
There is no error message. No failed build. No alert on your dashboard. The model just quietly settles into what works on paper and stops pushing further.
I keep seeing this across AI product teams. Most teams find out only when a real user tells them something is wrong, and by that point, the release has already gone out.

What I cover in this video:
[1:04] Why AI projects that demo well collapse completely when they meet real production infrastructure
[3:04] Only half of the teams run proper evaluations; most are shipping AI with no real way to know if it is actually working
[5:31] What useful observability actually looks like inside a working AI system
Your Training Metrics Are Lying to You

A higher reward score does not mean your model improved. It means your model got better at chasing the score, which is a very different thing.
The actual output quality can stay flat or get worse while every number on your dashboard looks healthy.
The model produces answers that sound correct rather than answers that are correct. You built a very efficient optimizer for the wrong thing.

A Stanford study found that developers using AI tools wrote less secure code but felt significantly more confident about it. That is exactly what a misleading metric does to a team.
When something breaks, the accountability question gets ugly fast. Microsoft and Google now have AI writing 25 to 30 percent of their code, and most teams still do not have a clear answer for who owns the output when it goes wrong.
If the Model Is Learning, Why Is Nothing Getting Better?
Most teams respond to a plateau by adding more data or running more training cycles. That is the wrong move. You are putting more fuel into a car that is driving in the wrong direction.

The teams leading the charge are doing three things you might not be doing.
Evaluating outputs against real user tasks, not internal benchmarks
Building checkpoints that catch when the model starts gaming the reward system
Rolling back to earlier versions, when numbers look good but outputs do not
When your team ships a model that peaked too early, your GTM motion follows that noise because nobody has told them otherwise. Your marketing launches features before the edge cases are handled.
Your sales team promises capabilities that will break under real conditions. And nothing damages customer trust faster than a product that almost works.
Ritesh Osta, who works with AI product teams on GTM execution, puts it plainly: the gap is not in the tools. It is in the handoff between engineering and the market, and his team has been fixing that handoff from the GTM side.
Ritesh Osta, who works with AI product teams on GTM execution, puts it plainly: the gap is not in the tools. It is in the handoff between engineering and the market, and his team has been fixing that handoff from the GTM side.
Your model did not fail you. Your scorecard did. And until you fix that, more data and more training will just make you more efficient at building the wrong thing.