
Your AI can see, hear, and read now. Are you building products like it?
Yesterday, I finished testing 5 multimodal models on the same workflow. Surprised to see that the real difference was not the model. It was everything around it.

Most product teams are still building AI, as it can only read text.
A customer sends a voice note explaining the issue. Then they attach a screenshot of the error. Then they type one more line because the problem is URGENT.
What does the product do?
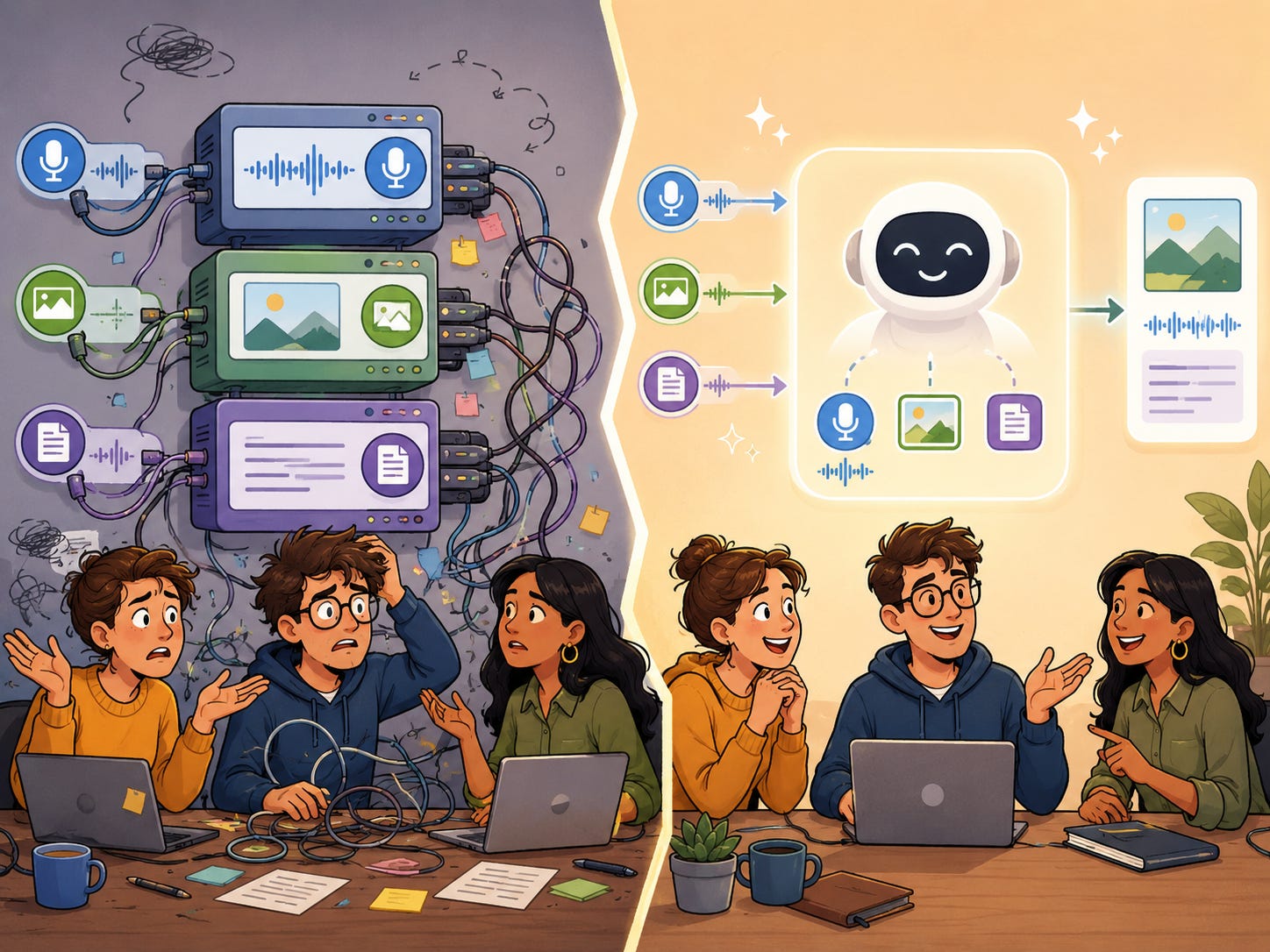
In most companies, it still splits the same customer problem into three separate systems.
One tool transcribes the voice
One model reads the screenshot
One LLM processes the text
Three API calls. Three bills. Three places where context can break.
Multimodal AI changes that.
Voice, image, and text can now be processed together in one workflow. But that does not automatically make the product RELIABLE.
This is where most teams get the story wrong!
The model is not the product. The workflow around the model is the product.
The real problem is not the model selection
Everyone is comparing AI models. Very few teams are comparing failure points.
That is why so many AI projects look impressive in demos and then collapse in production. (Check McKinsey Report)
The same three mistakes keep showing up:
Teams pick a model before mapping the workflow it needs to serve.
They run voice, image, and text through separate pipelines with no unified output layer.
They ship without an evaluation framework to know whether the system is actually working after launch.
So, before you ask which model is best, ask four boring questions:
What input comes in?
What decision needs to be made?
What action happens after the decision?
What needs to be traced when something goes wrong?
JP Morgan and Goldman Sachs both use the same approach. I covered the framework that separates the 39% seeing real returns from those stuck in pilot mode.
The same task. Five models. Very different results
I tested five multimodal models on the same task. A voice note, a screenshot of an error, and a typed description of the problem.
Same task. Same data. Very different results.
Here’s what I found.
GPT-4o — OpenAI - It is strong when speed and real-time troubleshooting matter the most.

Gemini 2.5 Pro — Google - It is better suited for long-context tasks, document-heavy workflows, legal review, and compliance checks.

Claude Opus & Sonnet — Anthropic - It is useful when accuracy, caution, and auditability matter more than speed.
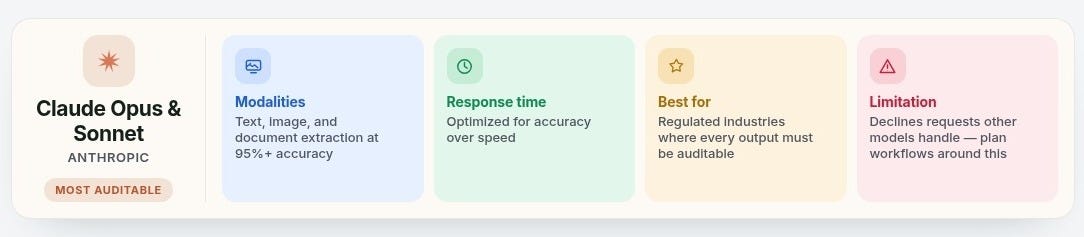
Llama 4 Maverick — Meta - It becomes relevant when the data cannot leave your infrastructure
Phi-4 — Microsoft - Manufacturing, field operations, and remote facilities are good examples.

But here is the part most model comparisons miss. Picking the right model only gets you to the starting line.
This is where teams get stuck.
The integration layer
The evaluation pipeline
The observability stack
The human escalation path
The governance layer
A multimodal system does not just answer a prompt. It may interpret a voice clip, read an error screenshot, pull information from a document, and trigger a downstream action.
Ritesh Osta and my team at Insightstap work specifically on building custom AI systems and agent applications which are production-ready, and not just demo-ready.
Further, what actually determines whether an agent system works in production or not is covered here in my video.

For a quick browse, go here:
3:04 — Can your team explain what happened?
4:46 — Can you trace which input influenced the decision?
6:21 — Can a human override the system before it damages the customer experience?
The limitations that a ‘No-Launch’ event will show you
Every model has a tradeoff.
GPT-4o loses precision on long document outputs
Gemini 2.5 Pro gets expensive quickly at scale
Claude declines tasks that other models handle without hesitation
Llama 4 needs two weeks of fine-tuning before it runs reliably in production
Phi-4 supports only 8 languages for audio input
None of these is a deal breaker! They become way too expensive after the team discovers them after the launch!
So, where does the human layer still matter?
Cause if humans are removed completely, customer experience is sure to get damaged. Some moments can be automated, but others might need humans in the loop, such as:
A refund dispute, a medical document, an insurance claim, a legal contract, or a high-value customer complaint should not be treated like a password reset.
In most cases, I have seen that companies are attentive before the sale. After the sale, they hide behind bots.
That is not an AI strategy. That is cost-cutting with a nicer dashboard. This is what made Klarna rehire 700 humans whom they had laid off earlier that year!
How would I pick the right model?
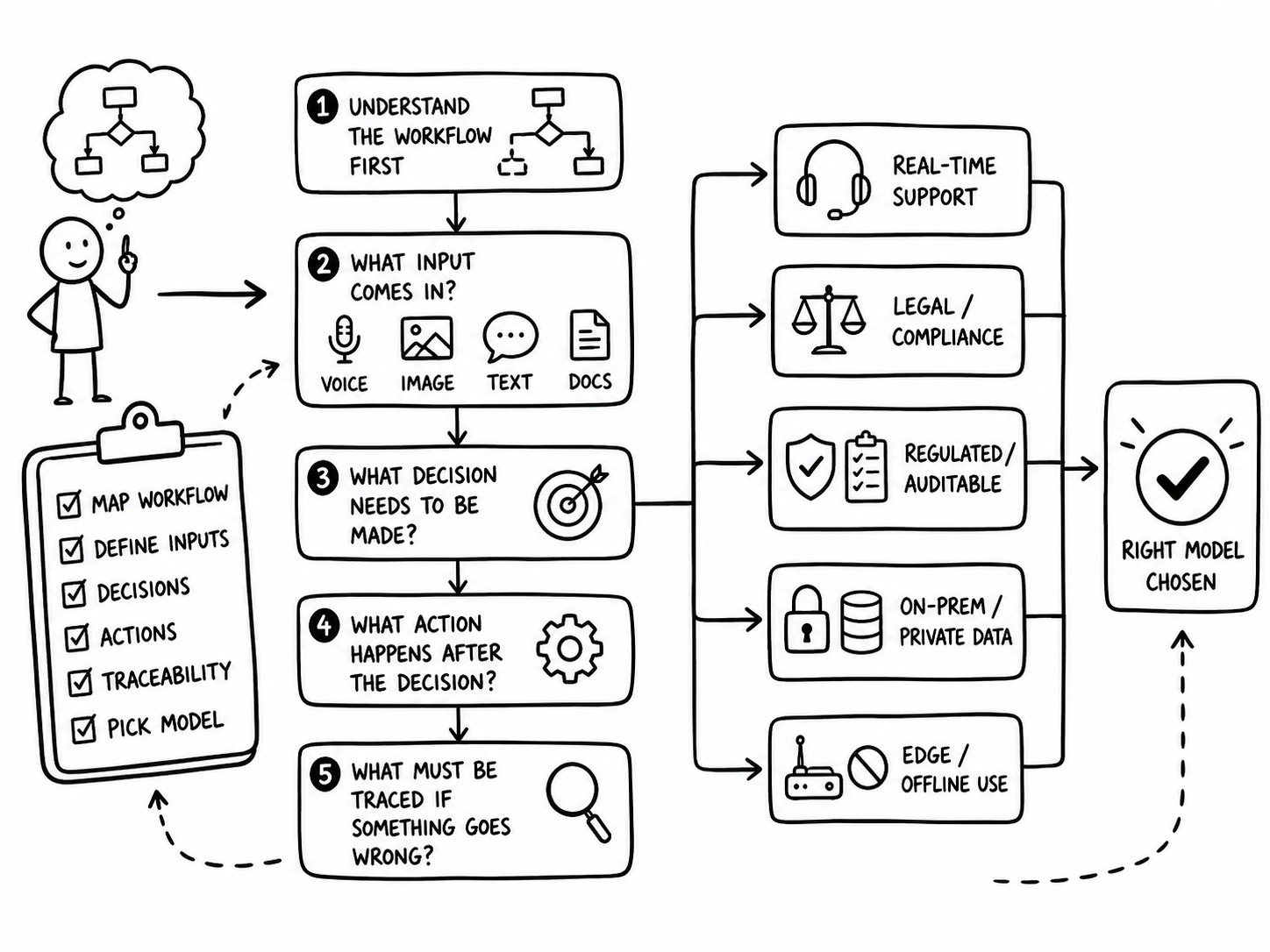
Picking the right model starts with knowing which tasks need automation and which need a human in the loop.
This is not a leaderboard. It is a workflow fit map. So here is what I recommend based on what I’ve seen while working with 100+ SaaS companies :
✅ For live customer support and real-time troubleshooting, I would start with GPT-4o
✅ For legal, compliance, and large document processing, test with Gemini 2.5 Pro
✅ For regulated industries with full audit requirements, I prefer to evaluate with Claude
✅ For teams where data cannot leave the building, it is advisable to look at Llama 4
✅ For edge deployments with no internet dependency, explore Phi-4
But I would not start by buying access to any of them. I would start by mapping one workflow completely.
Then I would choose the model.
The teams winning with multimodal AI are not building more impressive demos. They are building fewer failure points.
Subscribe to Swarnendu’s Newsletter
190+ subscribers, posts come every Wednesday on SaaS, AI, and GTM. Subscribe if that is the conversation you want to be part of.